|
Molecola del mese di novembre 2001
La struttura del DNA
ci rivela come la doppia elica codifica le informazioni genetiche
 DNA DNA
Ognuna delle cellule nel nostro corpo contiene circa 1.5 gigabyte di informazioni
genetiche, una quantità di informazioni che riempirebbe due CD
ROM. Sorprendentemente, quando viene introdotta in una cellula uovo, una
quantità di informazioni così modesta è sufficiente
a costruire un intero essere umano in grado di vivere, respirare e pensare.
Attraverso gli sforzi del progetto internazionale per la sequenziazione
del genoma umano, ora queste informazioni sono a disposizione di chiunque.
Tutti quindi possiamo valutarne la complessità e tentare di capirne
il significato. Nello stesso tempo, possiamo meravigliarci della loro
semplicità rispetto alla grande complessità del corpo umano.
Memoria a sola lettura
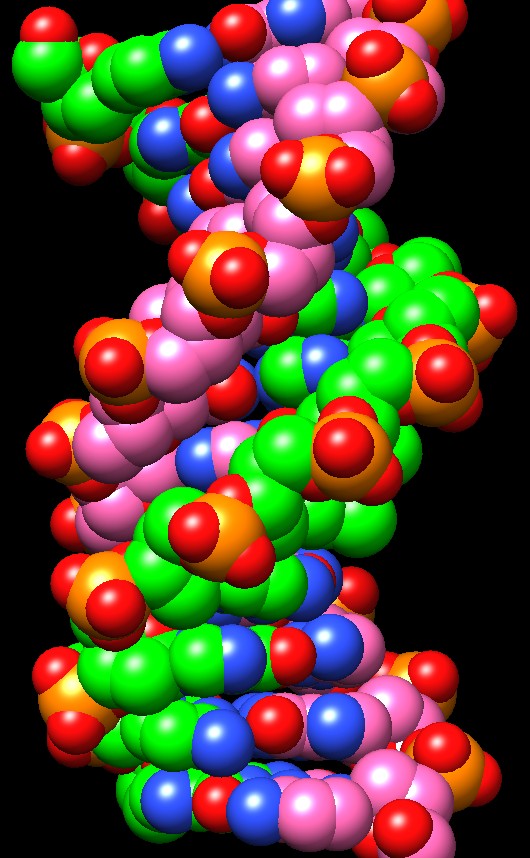
Il DNA è una memoria a sola lettura conservata
al sicuro nella cellula. L'informazione genetica viene immagazzinata
in modo ordinato nel DNA che è composto da due lunghi filamenti
lineari di milioni di nucleotidi appaiati tra loro in modo complementare.
Questi filamenti si avvolgono uno sull'altro per formare una doppia
elica, illustrata qui a fianco (file PDB 1bna)
dove una catena è mostrata con i carboni verdi e l'altra con
i carboni rosa. Il codice è piuttosto facile da leggere, basta
scorrere lungo il filamento di DNA, un nucleotide alla volta, e leggere
le basi: A, T, C o G. Questo è esattamente quello che fanno le
nostre cellule: leggono la sequenza di basi che interessa sul DNA e
la trascrivono su un RNA messaggero, poi usano i ribosomi per costruire
proteine corrispondenti a questo codice.
La nostra eredità
Le informazioni genetiche che abbiamo ereditato
dai genitori sono il nostro bene più prezioso. Hanno guidato
la costruzione del nostro corpo all'interno del grembo materno e continuano
ancora oggi a controllarne tutte le nostre funzioni vitali di base.
Ogni cellula sta usando continuamente queste informazioni per sapere
come controllare i livelli di zucchero nel sangue o la temperatura del
corpo, come digerire i diversi cibi, come affrontare le nuove sfide
ambientali e come risolvere migliaia di altri importanti problemi. Tutte
le risposte sono contenute nel DNA.
Centinaia di proteine diverse vengono costruite per interagire con queste
informazioni:
per attivarle o disattivarle a seconda delle necessità,
per leggerle ed usarle per costruire nuove proteine,
per copiarle quando la cellula si deve dividere,
per conservarle e proteggerle quando non vengono usate attivamente,
per ripararle quando il DNA è danneggiato da sostanze chimiche
o da radiazioni.
Icona centrale
Il DNA è certamente una delle molecole più
belle delle cellule viventi. La sua doppia elica ha una forma elegante
ed è piacevole da guardare. Il DNA è anche una delle molecole
più famose, l'icona centrale della biologia molecolare, riconosciuta
facilmente da tutti.
Per qualcuno può avere un significato negativo, essendo un simbolo
usato dagli attivisti contrari all'ingegneria genetica. Ad altri, può
ricordare i progressi che ci sono stati nelle indagini di polizia da
quando la prova del DNA è stata usata per risolvere molti casi
famosi. Molti hanno visto il DNA nei film di fantascienza, dove veniva
modificato per costruire dinosauri o per conservare dati nascosti degli
alieni. Per tutti è un simbolo penetrante della nostra crescente
comprensione del corpo umano e della nostra stretta parentela col resto
della biosfera. Molti problemi morali ed etici devono essere riconsiderati
alla luce di queste nuove conoscenze.
 Informazioni
molecolari Informazioni
molecolari
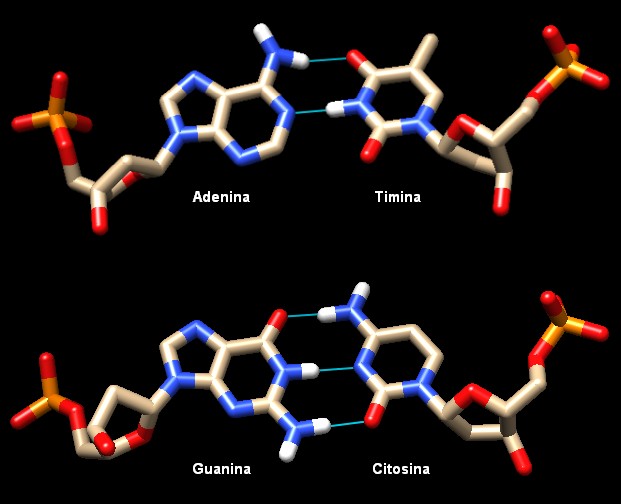
Il DNA è perfetto per l'archiviazione e la lettura di informazioni.
Ogni lato della molecola porta informazioni. Il meccanismo di base col
quale il DNA immagazzina e trasmette le informazioni genetiche è
stato scoperto negli anni 1950 da Watson e Crick. Queste informazioni
possono esere lette grazie al fatto che le basi azotate (adenina, timina,
guanina, citosina) possono formare tra loro dei legami idrogeno complementari
attraverso i quali possono riconoscersi ed accoppiarsi una con l'altra
su lati opposti della doppia elica (adenina si accoppia solo con timina,
guanina solo con citosina). Questi legami idrogeno sono mostrati qui
a fianco con fili azzurri, qui sotto con frecce rosse.
. . . . . . . . . . . 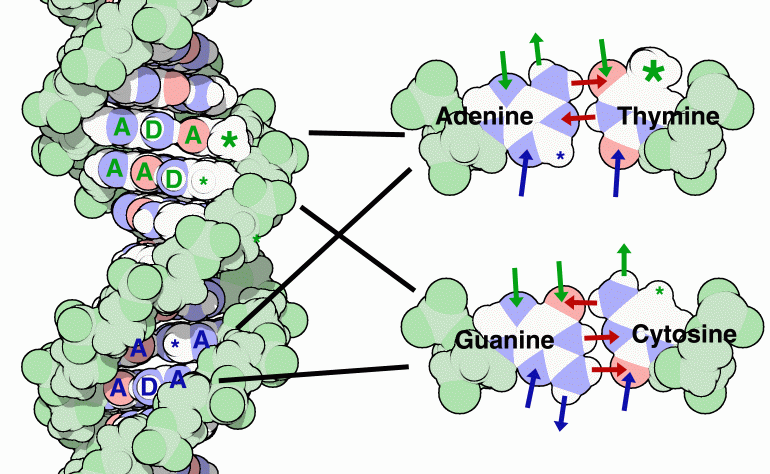
Ulteriori informazioni possono essere lette dalle superfici che rimangono
esposte nella doppia elica.
Nella scanalatura principale (la più larga delle due scanalature
del DNA), le differenti paia di basi hanno una sequenza caratteristica
di gruppi chimici che può essere riconosciuta. Questa sequenza
è mostrata da frecce verdi nelle figure sulla destra.
I gruppi includono donatori (D) ed accettori (A) di legame idrogeno
e inoltre un gruppo chimico di maggiori dimensioni nel paio di basi
adenina-timina (asterisco grande) o un gruppo più piccolo nel
paio di basi guanina-citosina (asterisco piccolo).
Anche nella scanalatura minore, c'è una sequenza caratteristica
di gruppi chimici che permettono di riconoscere le basi azotate, indicata
con frecce blu nella figura sulla destra e con lettere blu nella struttura
sulla sinistra.
Queste informazioni sono usate dalle proteine per leggere il codice
genetico del DNA senza svolgere la doppia elica, ma sono anche il bersaglio
di numerose tossine e farmaci che attaccano il DNA.
 Variazioni
sul tema Variazioni
sul tema
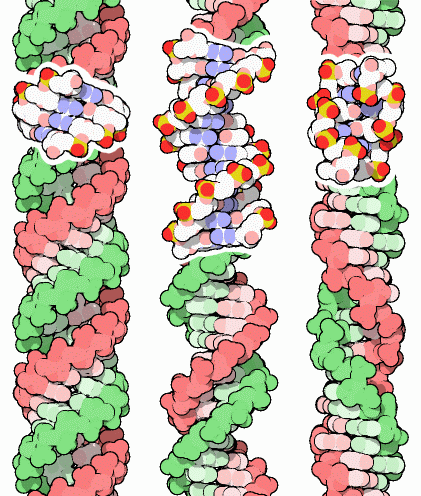
Il DNA adotta la normale doppia elica, chiamata elica-B,
quando si trova nelle condizioni tipiche che esistono nelle cellule
viventi. L'elica-B è mostrata nella figura al centro qui a lato
(file PDB 1bna) mentre nella parte sottostante
è illustrata una versione idealizzata di elica-B.
In condizioni diverse, comunque, il DNA può assumere altre strutture,
come è illustrato nelle altre due figure: file PDB 1ana
sulla sinistra e file PDB 2dcg sulla destra.
La doppia elica sulla sinistra, chiamata A-DNA, ha le basi inclinate
ed una profonda scanalatura principale. Si forma in condizioni disidratanti.
Anche l'RNA spesso assume questa forma, perché il gruppo idrossilico
extra presente sul ribosio si intromette, rendendo la forma B instabile.
Si veda, per esempio, la struttura ad elica-A dell'RNA
transfer (mdm 3/2001).
La doppia elica sulla destra è avvolta nella direzione opposta
(sinistrorsa) rispetto al A-DNA e al B-DNA, è chiamata Z-DNA.
Si forma a concentrazioni elevate di sale e richiede una particolare
sequenza di basi, con molte coppie alternate citosina-guanina e guanina-citosina.
 Esplorando
la struttura Esplorando
la struttura
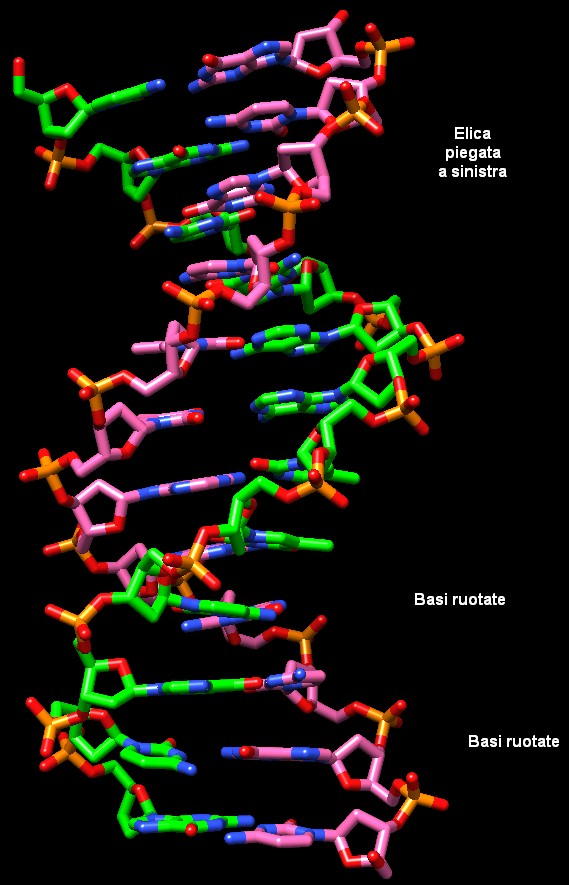
Molti pensano che il DNA sia una doppia elica perfetta e regolare. In
realtà ha molte variazioni locali di struttura. Il piccolo frammento
di DNA mostrato qui a fianco (file PDB 1bna)
presenta alcune delle variazioni più comuni.
Nella parte superiore, l'elica è piegata a sinistra, distorta
a causa del fatto che le eliche sono impaccate nel cristallo (queste
strutture si ottengono infatti da molecole cristallizzate).
In basso, due delle basi sono fortemente ruotate e quindi non
sono in un piano perfetto. Questo migliora il modo in cui le basi si
impilano una sopra l'altra lungo ogni filamento, stabilizzando l'intera
doppia elica.
A mano a mano che aumenta il numero delle strutture di DNA studiate,
sta diventando sempre più chiaro che il DNA è una molecola
dinamica, molto flessibile, che può essere piegata, attorcigliata,
annodata e snodata, svolta e riavvolta dalle proteine con cui interagisce.
 Bibliografia Bibliografia
Richard E. Dickerson (1983) The DNA Helix and How it is Read.
Scientific American 249, pp. 94-111.
Wolfram Saenger (1994) Principles of Nucleic Acid Structure (Springer-Verlag,
New York).
|
|
|
